 Naar de Nederlandstalige versie
Naar de Nederlandstalige versie
TETRA RustIEC
RustIEC is a VLAIO TETRA project (grant HBC.2021.0066) with the goal of teaching Flanders' companies proficiency in the Rust programming language. The project has a specific focus on secure IoT systems, secure edge computing, and secure cloud computing.
The RustIEC project is run by the Smartnets lab of the Vrije Universiteit Brussel, and the DistriNet lab of the KU Leuven. Meet the team!
Project goal
Problems with memory, such as memory leaks, buffer overflows, and memory dumps, are well-known issues with software that could be exploited by attackers. The amount of cyber attacks increases year after year. Not only large companies, but also smaller companies are more often the target of attacks, and could face severe consequences.
With most programming languages like C and C++, these issues with memory management are noticed late, usually during runtime. They might not appear during compilation or debugging. When these problems only become apparent in production, they can lead to great damage. The search to their root cause can also be time consuming.
The Rust programming language provides an adequate answer. The compiler will not allow the developer to write unsafe code. Inherently by its design, the amount of mistakes in written Rust code is lower. As a consequence, mistakes are more often avoided by their conception, which makes maintenance of software easier. Rust allows, at the same time, to write performant code. This programming language is well-documented, and many libraries are available for embedded systems as well as for regular platforms.
The most important goal of this project is to acquiant companies with the advantages that Rust could provide them, such that they can make the trade-off of using Rust for future projects for themselves.
We envision these results:
- Two complete case-studies, for which the code will be shared openly.
- Benchmarks made for comparing the performance of Rust and more mainsteram programming languages such as C, C++ and Python, for some frequent and representative algorithms in the IoT and security domains.
- Research to interoperability of Rust with other programming languages and the portability to other platforms.
- Research of the efficiency of conversion tools surch as C2Rust and CRUST.
- Organisation of one introductory and one more advanced hands-on workshop about learning Rust, and publishing the workshop material.
- Integrating the gained knowledge in at least three courses for both research institutions.
Project participants


















Naar de Nederlandstalige versie
The team
The RustIEC project is run by the INDI/ETRO Smartnets lab of the Vrije Universiteit Brussel, and the DistriNet lab of the KU Leuven.
Project supervisors




Kris Steenhaut (Vrije Universiteit Brussel) has been guiding the ETRO/IRIS/Smartnets group since 2005. Her research activities focus on the design, implementation and experimental evaluation of Wireless Sensor Networks and their integration in the Internet and the Word Wide Web. Topics of particular attention are interoperability, security and privacy as well as the interworking with fog and cloud. Kris Steenhaut has guided several ITEA and SBO projects and several EU projects on Internet of Things, smart grid, smart lighting and environmental monitoring. She plays an active role in development cooperation with Cuba and Vietnam.
An Braeken (Vrije Universiteit Brussel) became professor in 2007 at the Erasmushogeschool Brussel (currently since 2013, Vrije Universiteit Brussel) in the Industrial Sciences Department. Her current interests include security and privacy protocols for IoT, cloud and fog, blockchain and 5G security. She has cooperated and coordinated more than 12 national and international projects.
Jorn Lapon (KU Leuven) is a Research Manager in Secure Software of the DistriNet Research Group of KU Leuven located in Gent. He has been active in both industry and academics and obtained his PhD on Anonymous Credential Systems back in 2012. Topics of particular interest are IoT security, with a focus on secure development and security testing. His close collaboration with industry has proven to be valuable for both the companies and academic research.
Stijn Volckaert (KU Leuven) is een assistant professor bij imec-DistriNet, KU Leuven - Technology Campus Ghent. Zijn onderzoek focust op exploit mitigation, software diversity, multi-variant execution en geautomatiseerd overzetten van legacy code naar veilige programmeertalen.
Project collaborators




Ruben De Smet (Vrije Universiteit Brussel) has been actively developing in Rust since 2016, and has contributed to multiple Rust "crates", among which in the asynchronous ecosystem, the cryptographic ecosystem, and the "qmetaobject" library. He co-maintains a set of Signal libraries and develops a Signal client in Rust. For his PhD research, he works on a peer-to-peer application. Ruben joined the Belgium Rust User Group in 2017, and has been organiser of this group since 2020.
Diana Deac (Vrije Universiteit Brussel) recently started developing in Rust after working with Contiki-NG which is written in the C programming language. She designed an adaptive scheduler for Time Slotted Channel Hopping (TSCH) for Contiki-NG. She is currently working on implementing the RPL protocol in Rust. The focus of her PhD research is enhancing protocols for wireless sensor networks with security in mind.
Roald Van Glabbeek (Vrije Universiteit Brussel) contributes through his expertise on embedded platforms and design and implementation of MAC, RDC and routing protocols.
Andreas Declerck (Vrije Universiteit Brussel) has been working with Rust since 2017 and occasionally contributes to the Rust-written X11 window manager LeftWM. For his master's thesis, he is exploring the potential of using Rust to implement multicast in the RPL network protocol and CSMA on embedded devices. He is active in the art world, assisting artists with the technical aspects of their art installations. In his spare time, he is an active volunteer at CoderDojo Belgium, where he teaches children aged 7 to 18 how to program.
Project contributors



Thibaut Vandervelden (Vrije Universiteit Brussel) is a Rust crate contributor since 2019. His main focus is writing software for embedded devices that use low power wireless communication protocols, such as IEEE802.15.4. He has contributed to the smoltcp crate, where he implemented the 6LoWPAN protocol and is currently working on a RPL protocol implementation. The performance of the Rust programming language on embedded devices is the focus of his PhD research.
Robrecht Blancquaert (Vrije Universiteit Brussel) focusses on fast, safe implementations of elliptic curves for low-power embedded devices, with automatic specialisation for different CPU architectures.
Alicia Andries (KU Leuven) is a PhD researcher at the imec-DistriNet research group of KU Leuven under supervision of Stijn Volckaert. She werks on semi-automatic migration of code in unsafe programming languages to safer alternatives, such as Rust. For example, she works on translating drivers to Rust, researching the current limitations of automatic migration tools, and she researches Rust for Linux.
Naar de Nederlandstalige versie
Workshops
Part of the RustIEC project goal is the organisation of at least one introductory and two advanced hands-on workshops about learning Rust.
RustIEC 101
RustIEC 101 is our introductory Rust course, based on the A-modules of the "101-rs" course by Tweede Golf. The materials are available at https://101.rustiec.be/, and the source code is available at https://gitlab.com/etrovub/smartnets/rustiec-101/.
Part 1
This course will be taught in the form of two workshops on:
- March 14, 2023 on the VUB campus;
- March 27, 2023 on the VUB campus;
- March 28, 2023 on the VUB campus;
- November 8, 2024 on the VUB campus;
with a total expected participant count of 35.
Part 2
The second part of the RustIEC 101 course teaches more advanced features of the Rust language.
- September 13, 2023 on the VUB campus;
- October 19, 2023 on the Barco campus;
- November 8, 2024 on the VUB campus.
RustIEC 201: Embedded programming
The "RustIEC 201: Embedded programming" workshop aims to provide you with an insight into the world of embedded Rust. The contents of the workshop are hosted on our website https://201.rustiec.be/.
This course was thought on March 25, 2024 and on November 26, 2024.
RustIEC 202: C2Rust
The "Advanced: C2Rust" workshop is designed for members looking to deepen their understanding of Rust through practical applications. This workshop extends the foundational knowledge from RustIEC 101, offering participants hands-on experience with the C2Rust tool, which helps in the migration of C codebases to Rust.
The course material can be found on https://github.com/AliciaAndries/rustiec_workshop_steps.
This course was thought on December 12, 2023, right after the User Committee meeting.
Naar de Nederlandstalige versie
Contact
For questions that are directly related to the study area of one of the collaborators or contributors, feel free to directly contact the relevant team members.
General questions or joining the project
Would you have interest in joining the project with your company, you can contact An Braeken and Kris Steenhaut.
Technical questions and suggestions
For questions pertaining to the content of the project, you can directly contact the collaborators and contributors.
Web, cloud and async
For questions regarding cloud or web technology, or for asynchronous programming, you may contact Ruben De Smet.
Embedded programming
For questions regarding embedded programming, you can contact Thibaut Vandervelden and Diana Deac
Automatic translation and Linux kernel drivers
For questions pertaining to automatic translation or Linux kernel development, you can contact Stijn Volckaert en Alicia Andries.
Naar de Nederlandstalige versie
Kick-off meeting November 24 2022
Ruben De Smet: RustIEC kick-off

Download slides "kick-off introduction"
Stijn Volckaert: Safe Systems Programming in Rust

Download slides "Safe Systems Programming in Rust"
Ruben De Smet & Thibaut Vandervelden: the Rust ecosystem

Download slides "Rust Ecosystem"
Naar de Nederlandstalige versie
User committee meeting March 27 2023
Ruben De Smet: committee meeting overview

Alicia Andries: C to Rust and making unsafe code safe

Thibaut Vandervelden: smoltcp

Naar de Nederlandstalige versie
User committee meeting December 12 2023
Jorn Lapon: Welcome with coffee
Ruben De Smet: Vulnerabilities in Rust programs

Download Vulnerabilities slides
Alicia Andries: Incremental Migration of C-code to Rust

Download Incremental Migration slides
Naar de Nederlandstalige versie
User Committee meeting June 5 2024
Alicia Andries: overview user committee meeting

Alicia Andries: Evolution of Rust for Linux and Lessons Learned

Thibaut Vandervelden: Rust Operating Systems and Frameworks for Embedded Devices

Michael Allwright: WebAssembly and Rust

Jeroen Gardeyn: How Rust boosts confidence and productivity
my experiences as an algorithm researcher

Naar de Nederlandstalige versie
Embedded demo at Wireless Community Meeting - October 9, 2024
Based on our embedded workshop, we produced a small demo for the Wireless Community (WiCo) meeting on secure IoT on October 9, 2024. The demo extends the workshop with wireless control over a IEEE 802.15.4 TCP/IP network.

Naar de Nederlandstalige versie
Cybersecurity Industry Day November 14 2024
Based on our embedded workshop, we produced a small demo for the Cybersecurity Industry Day 2024 on November 14, 2024. The demo extends the workshop with wireless control over a IEEE 802.15.4 TCP/IP network. This is the same demo as for the Wireless Community meeting, but emphasizes the secure programming aspect over the wireless stack.

Additionally, the RustIEC project was summarized in a presentation at this event.

 Naar de Nederlandstalige versie
Naar de Nederlandstalige versie
RustIEC newsletter (June 2023)
Welcome to the first newsletter for the RustIEC project. First, we would like to thank the participants of the first Rust Hands-On workshop, for which we received very good and insightful feedback. In September, the second session of this Rust Hands-On workshop will take place. Based on the results of the questionnaire, we decided that a specialized workshop at a later date will be focussed on embedded programming using Rust.
In this newsletter, we provide you with updates on the progress made by the RustIEC teams.
RPL implementation by Vrije Universiteit Brussel
The VUB team is currently finishing the implementation and evaluation of the Routing Protocol for Low-power and lossy networks called RPL. The implementation is written in Rust and added to the smoltcp TCP/IP library, a lightweight TCP/IP protocol stack. As an embedded operating system, we used the Embassy framework. Both are written in the Rust programming language.
 Figure 1: Protocol and application stack of Embassy with smoltcp and Contiki-NG.
Figure 1: Protocol and application stack of Embassy with smoltcp and Contiki-NG.
We used a simulator to evaluate the correctness of the RPL implementation, as a first step. Afterwards, real devices were employed, specifically the nRF52840 development kit. The network under evaluation consisted of devices running the smoltcp RPL implementation with the Embassy framework and devices running the well-established Contiki-NG RPL implementation, written in C, which is part of the Contiki-NG operating system. Figure 1 illustrates the protocol stacks for both smoltcp and Contiki-NG.
The testbed comprised of three nodes, as depicted in Figure 2. One of the nodes served as the root, another acted as a router, and the third operated as a leaf node. Multiple setups were evaluated, combining the Contiki-NG implementation with the smoltcp implementation. This approach aimed to test the compatibility of the Rust RPL implementation against an existing RPL implementation written in C.
 Figure 2: Testbed of nRF52840-DK's running smoltcp and Contiki-NG.
Figure 2: Testbed of nRF52840-DK's running smoltcp and Contiki-NG.
The Rust-based RPL with smoltcp is robust, but requires 145.5 KB of flash memory, whereas RPL with Contiki-NG in C requires 47.7 KB. The firmware without RPL requires 117.3 KB for smoltcp and 38.1 KB for Contiki-NG. However, it is important to note that this Rust implementation is a first iteration, leaving ample room for optimization and further refinement.
The VUB team worked, in collaboration with a master student, on the implementation of the Generic Header Compression (GHC) protocol. This protocol serves as an extension of the 6LoWPAN adaptation layer for IPv6. The implementation was also added to the Rust smoltcp library. After the evaluation, they concluded that GHC demonstrates its utility primarily in specific scenarios. IPv6 addresses are part of the dictionary used in the compression algorithm, resulting in only being efficient when the payload to be compressed contains IPv6 addresses.
The VUB team is now focussing on researching how to implement the Data Link layer in Rust for embedded devices, more specifically, Medium Access Protocols (MAC) such as Carrier Sense Multiple Access (CSMA) and Time Slotted Channel Hopping (TSCH). When these protocols are implemented in Rust, a full stack in a safe programming language is available for devices using the IEEE 802.15.4 standard.
Progress on C to Rust transpilers by KU Leuven
The KU Leuven team finished their case study of the Rust for Linux kernel. They successfully made a prototype of a parallel port driver in Rust and have learned some important lessons on the interoperability of C and Rust. For example, you should consider the kind of security features you added to the C code, and whether they ought to be added to the Rust code. Domen Puncen Kugler has uncovered some interesting examples of this. Also, if you translate a part of your C code base to Rust you will have to use a lot of unsafe calls to be able to interact with the C code from the new Rust code. It is important to wrap such unsafe functions in safe ones that can do memory safety checks before simply letting Rust code use a pointer that was provided by C code. While the KU Leuven team may have set aside their study of the Rust for Linux kernel for the time being, they are keeping an eye on significant developments. For example, the further Rust integrations into the mainline Linux kernel with the release of kernel version 6.2. The Rust integrations for this version are mostly low-level support code. It will still be quite a long time before any substantial Rust driver will be supported by the mainline kernel.
The KU Leuven team is currently evaluating the state-of-the-art on automatically translating C into safe Rust. The three publications of particular interest are Mehmet Emre et al.’s OOPSLA 2021 paper "Translating C to Safer Rust", Bryan Tan Yao Hong’s MSc thesis entitled "From C Towards Idiomatic & Safer Rust Through Constraints-Guided Refactoring", and Hanliang Zhang et al.'s VAC 2023 paper "Ownership guided C to Rust translation" They discussed the two first papers at the previous user group meeting. All three publications have very distinct techniques for transforming C to safe Rust, but they all use C2Rust by Immunant as a stepping stone as it can generate non-idiomatic unsafe Rust from C code. C2Rust does not aid in making a program safer or proving a program was safe in the first place. All it was built to do is make a syntactical translation. However, this syntactical translation does already remove a first hurdle for anyone trying to generate idiomatic Rust code from C code.
Because all three publications do use C2Rust, the start of their workflow is very similar. They all follow the workflow shown in Figure 3. They first use C2Rust to generate unsafe Rust, then they add their own contribution in the Refactoring block. While the papers share a similar workflow for transpiling, they have different ways of evaluating the effectiveness of their tools which makes comparing their different architectures arduous.
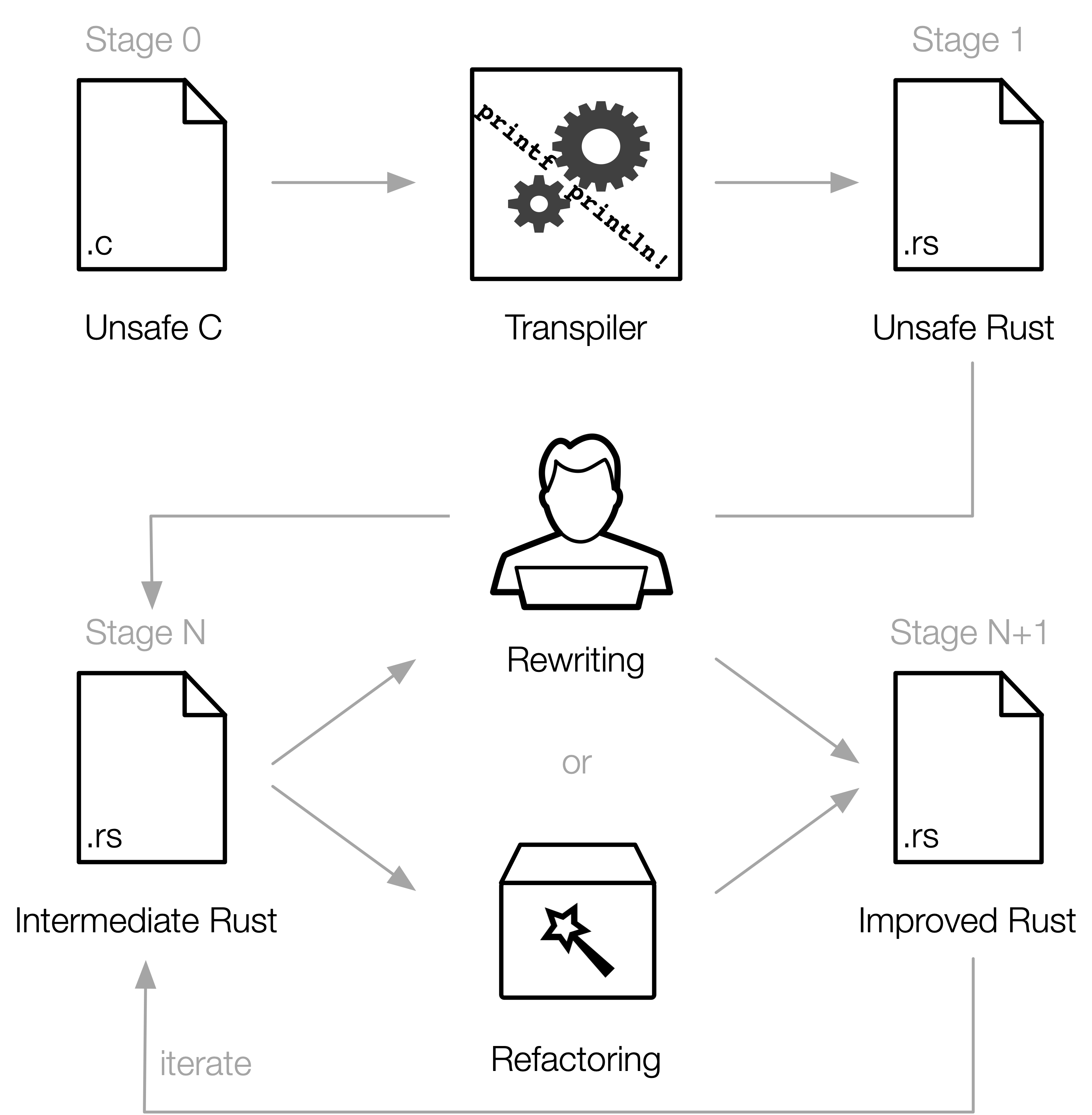 Figure 3: overview of the workings of C2Rust.
Figure 3: overview of the workings of C2Rust.
Mehmet Emre et al.'s architecture is the most straightforward. They simply transform every pointer of a specific type they come across to a Rust reference. If the transformations do not compile, they automatically look at the compiler errors and the proposed fixes and apply those. This is a very aggressive technique. The architecture proposed by Bryan Tan Yao Hong on the contrary, is very precise. They prepare transformations for some very specific cases like transforming array pointers into Rust types. Lastly, Hanliang Zhang et al.'s proposed architecture is based on finding pointers that fit into Rust's ownership model. The basics of the idea are very much like those of Immunant's Ownership Analysis.
After extensive experimentation, the KU Leuven team found that all the designs show promise, but the implementations of these architectures have several fundamental design flaws and shortcomings. The KU Leuven team is currently summarizing the strengths and weaknesses of the designs and will then formulate guidelines and recommendations that should serve as a starting point for a new and improved design.
Naar de Nederlandstalige versie
RustIEC newsletter (September 2024)
Welcome to the second newsletter for the RustIEC project. In this newsletter, we provide you with updates on the progress made by the RustIEC teams.
RustIEC demo at IMEC's Wireless Community event
Wednesday October 9, 2024, at IMEC - Leuven (12h - 19h) we will showcase RustIEC's results on secure embedded programming in Rust. We will demonstrate a wireless version of the pong game which we presented during our embedded workshop. The main topic of IMEC's Wireless Community even of October 9th is Secure over-the-air firmware updates of IoT devices, but the scope is broader.
Subscriptions via Wireless Community Workshop.
Rust Embedded Operating Systems and Frameworks
The VUB team submitted Overview of Rust Embedded Operating Systems and Frameworks to the MDPI Sensors journal, which was accepted for publication. The paper focuses on several Rust-based OSes and frameworks, including Tock, Hubris, RTIC and Embassy, It shows the potential of Rust offering a high-level language, without sacrificing low-level control or memory safety, making embedded systems more reliable and secure. Each OS brings something unique, from real-time capabilities to hardware abstraction, tailored to meet the challenges of modern embedded devices.
The first part of the paper covers the basics of the embedded Rust landscape, explaining how Rust can be used to write firmware for microcontrollers. It also explains the benefits of using asynchronous Rust for embedded systems, providing a more efficient and structured way to interact with peripherals. The most important parts of an embedded OS are also discussed, such as how tasks are scheduled, how processes communicate, how to interact with hardware, and finally how these OSes and frameworks handle networking.
The final part of the paper provides an evaluation of the interrupt and scheduling latency for each of the different OSes and frameworks. The results show that Rust-based OSes and frameworks can achieve low latencies, making them suitable for real-time applications. The memory requirements of each OS are also compared.
Crabstick: a chess engine in Rust
Thibaut and Ruben of the VUB team built a chess engine in Rust called Crabstick. This Friday-night hobby project is a work in progress, but it already plays a decent game of chess. You can play against Crabstick on Lichess.
The Lichess-integration is an interesting case study of how to integrate Rust with a web service: Crabstick is deployed as a Kubernetes service, and it can scale up to handle multiple games at once. Every game is handled by a separate worker deployment, which communicates with the main manager via a REST API. The worker deployment is implemented as an Actix actor, and exposes the games to Prometheus.
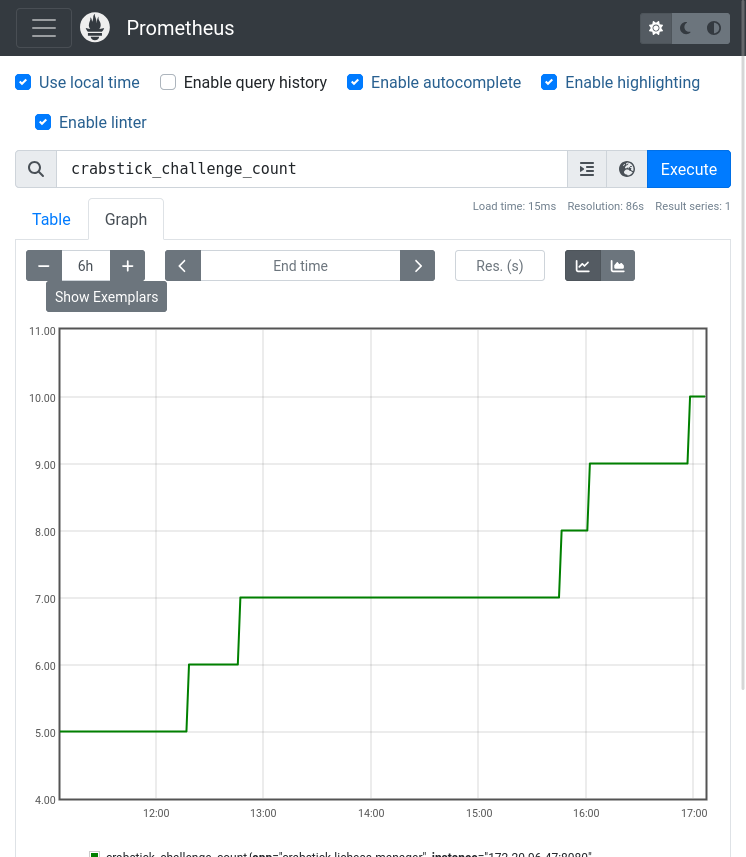 Figure 1: Crabstick statistics in Prometheus, showing the number of games played over time.
Figure 1: Crabstick statistics in Prometheus, showing the number of games played over time.
You can already have a look around the Crabstick source code. At a later time, we plan to make a comprehensive report on user space Rust tools and techniques.
Onwards Into the Breach
Over the duration of the RustIEC project Rust has been gaining more traction than ever. It is no longer only big companies like Google, Android, and Mozilla that are sharing their positive experiences with using Rust, governments are also getting involved. The White House now advises that new code ought not to be written in memory unsafe languages like C and C++, but instead should be developed in memory safe languages like Rust.
Translating C to Rust
Both academia and industry are making great strides in reducing the challenges of adopting Rust in systems level software. One domain that we have spent quite some time on during RustIEC, which is especially gaining interest, is automatic translation from C to Rust. The Translating All C to Rust(TRACTOR) program introduced by the Defense Advanced Research projects Agency (DARPA) is one indication of the growing interest. Hanliang Zhang et al., Jaemin Hong, Jaemin Hong et al., and Mehmet Emre et al. propose solutions based on program analysis while Momoko Shiraishi, Hasan Ferit Eniser, and Yoshiki Takashima propose solutions based on machine learning. Both angles have their pros and cons. While program analysis techniques aim to translate very specific code patterns, the code before and after transformation is very unlikely to have changed semantically. On the other hand, machine learning approaches are more holistic, and can cover whole code bases. However, they do come with a cost, and that is semantic equivalence. There is a significant probability that the code after the transformation will no longer compile, or the new program may exhibit completely different behavior. The future, therefore, will likely be a marriage between the two angles along with some extensive verification of the resulting program.
While TRACTOR is aiming for fully automated translations, either with program analysis or AI, or a combination of both, we have been looking into what tools we can provide until a reliable and usable fully automated translator is available. While we do believe that a fully automated translator is the future, there is no telling how long it will take before such a program can be trusted to operate on real infrastructure. In the meantime we propose a semi-automated tool that provides suggested translations in order of criticality to a developer who then decides whether those changes would be semantics preserving. While this means there is more manual labor necessary, this proposal also comes with more semantics preserving guarantees.
C and Rust Interoperability
While it remains impossible to translate whole codebases completely from C to memory safe Rust, using C and Rust together is a must. Thankfully Rust was designed with C interoperability in mind, so it is a mostly solved problem. The how of the matter is answered, however, whether we should do it in the first place wasn't asked during RustIEC. This question has popped up in recent literature. The concern explored by Michalis Papaevripides et al. and Samuel Mergendahl et al. is that unexploitable memory errors in hardened C code, that are passed to Rust code, could be used to exploit the memory safe Rust code. Since this attack was formulated Inyoung Bang et al., Peiming Liu et al., Hussain Almohri, Paul Kirth, and Elijah Rivera have proposed memory separation techniques such that the possibly corrupted C data can never corrupt Rust data. These protections still have some drawbacks, confused deputy attacks are not covered and, most importantly, the current tools are prototypes, so not industry ready.
Translation and Interoperability in the Real World
We used the Rust for Linux kernel as a case study to see how the introduction of Rust into a C code base is done in the real world. On the front of translating C to Rust, the maintainers of the Rust for Linux kernel chose to redesign when translating, instead of creating a one to one translation. More impactful than that were the large API and design changes throughout the duration of the RustIEC project, which we covered in the user group meeting on the 5th of June. However, the Rust for Linux kernel seems to be stabilizing and new Rust features are slowly but steadily being added to the mainline Linux kernel. One point of contention that seems to remain is how the Rust and C code should interface as there are few semantic definitions available for the C API. Therefore, on the front of C and Rust interoperability the main issue seems to be communication between the rather disjoint C and Rust maintainers and, at least for the time being, not security issues.
Questions or Suggestions?
If you have any questions or suggestions, feel free to reach out to us:
- General questions about the RustIEC project: An Braeken and Kris Steenhaut
- Technical questions about Web, Cloud and Async: Ruben De Smet
- Technical questions about Embedded Rust: Thibaut Vandervelden and Diana Deac
- Technical questions about Automatic translation and Linux kernel drivers: Stijn Volckaert and Alicia Andires
(L1.1) Rust: pros and cons
Rust is a compiled systems programming language, like C and C++. Each language has its own strengths and weaknesses. The following are the advantages (non-exhaustive) of Rust compared to C and C++.
-
Memory safety: Rust has a strong ownership system and borrow checker that enforces strict rules at compile time, preventing common memory-related errors such as null pointer dereferencing, dangling pointers, and buffer overflows. This can lead to more reliable and secure code.
-
Zero-cost abstraction: Rust provides high-level abstractions without sacrificing performance. The ownership system allows for fine-grained control over memory allocation and deallocation, and the language includes features like pattern matching, algebraic data types, and type inference that enable expressive code without runtime overhead.
-
Community and ecosystem: Rust has a growing and active community that values safety, performance, and modern software engineering practices. The Rust ecosystem includes a package manager (Cargo) that simplifies dependency management and makes it easy to integrate third-party libraries.
-
C compatibility: Rust can be easily integrated with C and C++ code. It provides foreign function interface (FFI) capabilities that allow Rust code to call C functions and vice versa. This makes it feasible to gradually introduce Rust into existing C or C++ projects.
-
Built-in Testing: Rust has a built-in testing framework that makes it easy to write and run tests. Testing is considered an integral part of Rust development, and the language encourages developers to write tests for their code, promoting a culture of code quality and reliability.
However, Rust also has its own disadvantages (non-exhaustive):
-
Steep learning curve: Rust has a steeper learning curve compared to C and C++. The ownership system and borrow checker introduce new concepts that may be unfamiliar to developers, especially those who are new to systems programming.
-
Maturity of the Ecosystem: While Rust's ecosystem is growing rapidly, it may not be as mature as C++'s, which has been around for much longer. C and C++ have well-established libraries and frameworks for various domains, and Rust may still be catching up in certain areas.
-
Limited Legacy Code Support: C and C++ have a large codebase in existing projects, and Rust's integration with legacy C or C++ code might not be as seamless as using these languages together. There may be additional effort required to interface with existing codebases.
-
Limited support for some architectures: While Rust supports many architectures, it might have limited support for very niche or specialized platforms compared to C and C++, which have been used in a wide range of environments for a longer period.
It's important to note that while these considerations highlight potential disadvantages of Rust compared to C, Rust brings significant advantages in terms of memory safety, concurrency, and modern language features.
More information about the pros and cons of Rust can be found in Stijn Volckaert's presentation.
(L1.2) Rust: tools and interoperability
The Rust ecosystem is rather young, but grows quickly and contains quite many high-quality tools and libraries ("crates"). We presented an overview of the Rust ecosystem in November 2022, which is hereby summarized.
-
Cargo, Crates.io, Docs.rs, Lib.rs, Rust Analyzer: Central to the Rust development environment are tools designed to streamline development of Rust code. Cargo is the de facto package manager, automating tasks such as building, testing, and project management. Crates.io functions as the primary repository for Rust packages, facilitating seamless sharing and discovery of libraries. Docs.rs automates documentation generation for crates, while Lib.rs serves as a community-driven catalog for alternative crate exploration. Rust Analyzer offers a sophisticated language server for enhanced IDE features, and ties into several different IDEs.
-
FFI: c2rust, cbindgen: In the domain of interoperability between Rust and C, c2rust and cbindgen are notable projects. c2rust is a tool expressly designed for the migration from C to Rust, facilitating the conversion of C code to Rust. cbindgen automatically generates C bindings for Rust code, offering communication between Rust and C components.
-
Rayon, Crossbeam: Parallelism is a cornerstone of Rust's design philosophy, and two libraries, Rayon and Crossbeam, contribute significantly to this paradigm. Rayon simplifies data parallelism, providing an accessible means to craft parallel code. Crossbeam, meanwhile, offers essential low-level building blocks for concurrent programming, addressing synchronization and parallelism requirements.
-
env_logger, log: In the domain of logging, Rust offers tools such as env_logger and log. The env_logger crate, configurable through environment variables, and log, a flexible logging facade, collectively empower developers to adopt logging practices tailored to specific project requirements. Many other logging backends exist for
log, andlogis the de-facto standard libraries. -
thiserror, anyhow: Rust's capabilities in error handling are extended through the thiserror and anyhow crates. The thiserror crate provides a straightforward mechanism for defining custom error types, while anyhow offers a versatile framework for handling any error types, simplifying error management within Rust applications.
-
Serde: Serialization and deserialization are fundamental tasks in software development, and serde stands as Rust's premier library for these operations. Supporting a diverse array of data formats, Serde ensures seamless data exchange within Rust applications through subcrates such as
serde_json. -
AreWeAsyncYet.rs, AreWeGameYet.rs, AreWeWebYet.org, AreWeLearningYet.com, ...: Community-driven initiatives, encapsulated in websites like AreWeAsyncYet.rs, AreWeGameYet.rs, AreWeWebYet.org, AreWeLearningYet.com, serve as comprehensive resources tracking Rust's progress across diverse domains. These platforms offer valuable insights into Rust's evolution in areas such as asynchronous programming, game development, web development, learning resources, and community well-being.
-
Async-Await: Rust introduces language-level features in the form of async-await syntax to facilitate the development of asynchronous code. This syntax enhances code readability and maintains a commitment to the principles of safety and concurrency. A whole ecosystem is being very actively developed around this asynchronous programming paradigm; see below.
-
Tokio, Mio, Async-std: Asynchronous programming is pivotal in modern software development, and Rust provides robust solutions through Tokio, Mio, and async-std. Mio provides a zero-cost asynchronous I/O library, and serves as the I/O framework for most asynchronous executors. It abstracts away from operating system specific asynchronous APIs, but does not provide async-await integration. Tokio functions as a runtime for asynchronous applications, and provides a whole framework to work with asynchronous I/O with async-await syntax. Async-std offers utilities for asynchronous programming, and serves as an alternative to the now more popular Tokio. Collectively, these crates empower developers to build efficient and scalable systems
-
Hyper, Actix-Web: For web development in Rust, libraries such as Hyper and frameworks like Actix-Web play essential roles. Hyper offers a fast and low-level HTTP implementation both at client and server side. Actix-Web is a powerful and ergonomic web framework. Both projects are built on top of the asynchronous Tokio framework.
-
Wasm-Pack, Yew: In the context of WebAssembly (WASM) and web development, Rust is one of the major go-to languages. Rust offers tools such as wasm-pack. This utility streamlines the building and integration of WebAssembly projects. Yew, a Rust framework tailored for client-side web applications, leverages the power of Rust and WebAssembly to deliver a seamless and performant web development experience.
In summary, the Rust ecosystem boasts a collection of sophisticated tools and libraries that collectively enhance the development experience, addressing a wide spectrum of programming needs. These tools and libraries were presented during our kick-off meeting, during the "ecosystem" presentation, which was presented by Ruben and Thibaut.
(L1.3) Benchmarking Rust against C and C++
Rust and C are compiled languages that use the LLVM code generation tool, implying comparable runtime speed and memory usage. However, due to differences in programming styles, it's challenging to make assertions about their performance. Various Rust language-specific overheads contribute to this complexity:
- In Rust, slices and str are represented by a pointer and the element count. When passed to a function, both the pointer and element count are transmitted. In contrast, C might only require a pointer, assuming the size is known or inferred from context.
- Bound checks are inserted by the compiler when indexing an array. In most cases, these bound checks can be optimized out by the compiler. This can prohibit the compiler to do autovectorization of some operations.
- In some cases, the Rust borrow checker is too strict, simply because that edge case is not implemented by the compiler. For these cases, adding copies or use reference counting is the solution. Lukely, there are very few edge cases where this is necassery.
- Using generics in Rust can potentially increase the executable size, as the compiler generates optimized functions for each type used with a generic function, leading to multiple instances in the binary.
Rust also has places where it ends up being more efficient and faster than C:
- Struct fields are reordered to minimize padding, enhancing memory utilization.
- Rust is good in inlining functions, even those from dependencies.
- Rust makes optimized versions of generic implementations, like C++ templates.
This is not possible with C, where macros need to be used or less efficient implementations with
void*. - Rust enforces thread-safety, even for dependencies.
Examing benchmarks, such as c-vs-rust benchmarks, shows that Rust outperforms C in 7 out of 10 benchmarks. In the c-vs-rust from the Benchmark games, Rust is fastest in 5 out of 10 benchmarks.
We also ran our own benchmarks, benchmarking 3 sorting algorithms written in Rust and in C. These algorithms were implemented in a straightforward manner, without any specific focus on code optimization. Utilizing Criterion, a benchmarking tool in Rust, we performed multiple runs of sorting arrays with random data across various sizes. The benchmarks ran on an HP EliteBook 745 G6 running Fedora 39. The following graphs depict the performance of each sorting algorithm's Rust implementation, its C counterpart, and the built-in standard library sorting function.
Bubble sort
For Bubble sort, the compiler is unable to optimize all bound checks for indexing arrays. Note that we consider this as an optimization that is missed by the compiler. The Rust compiler still has places where optimizations are lacking.

Quick sort
Performance of Quick sort is around equal for the Rust and C implementations.

Heap sort
For the Heap sort implementation, the Rust version is faster than the C implementation.

Conclusion
Comparing the performance of Rust and C can be challenging since both are compiled languages sharing the same compiler backend (LLVM). While a comparison using the GCC compiler for C is possible, it introduces a comparison between GCC and LLVM rather than a comparison between the languages themselves.
Note that Rust has a rich standard library.
Sorting anything that is sortable can be achieved by just calling the .sort() method.
This feature contributes to Rust's rich and user-friendly programming environment.
(L2.1) Automatic conversion and interfaces
While Rust may be rapidly gaining popularity, many code bases are still primarily written in C. It is therefore important to make sure Rust is as painless as possible to introduce into an existing C code base. The foreign function interface options provided by Rust make communicating between C and Rust easier. If you want to translate C code to Rust, you can use C2Rust to speed this process along.
Automatic Conversions
Automatic conversion from C to Rust is possible, if not yet perfected. The current state-of-the art tool is C2Rust. More Information about the automatic conversion from C to Rust can be found in the presentation on Migrating From Unsafe Languages to Rust.
Interfaces
To call Rust from C or C from Rust, all you need are the correct bindings of the desired functions. Such bindings are simply the function headers expressed in the language you want to call them from. When a Rust binding of a C function is desired, one must create a Rust binding from a C header. For example, the C function header below:
void function(int i);
The following binding is needed to call the function from Rust:
#![allow(unused)] fn main() { extern "C" { pub fn function(i: ::std::os::raw::c_int); } }
Rust provides types that are identical to C types in the standard library to make interoperability between C and Rust easier. To create a Rust binding that represents a C function, it is necessary to add extern "C" to let the Rust compiler know you will be linking to external code.
Bindings can not only be made for functions but also for structs. In the case of structs, it is important to add #[repr(C)] as it makes sure the alignment, size, and order of fields are the same as in C.
When creating a C binding from Rust code, you need to add some information to the Rust function. The compiler needs to be told not to mangle the function name, so the attribute #[no_mangle] must be added. The keyword extern "C" must be added to the function header to make sure that this function can be correctly used by a C program.
#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn function(i: i32); }
The following binding is needed to call the function from C:
void function(int i);
Creating bindings for your interfaces so C and Rust can talk to each other is banal work and can be done in an automated fashion.
Bindgen was introduced to create Rust bindings from your C code.
All you have to do to create such a binding is provide a C header file that contains all that should be callable from Rust code. Creating C bindings from Rust can also be automated with the tool cbindgen. Cbindgen needs some more help than bindgen, some configuration information must be provided. This can either be achieved by adding a cbindgen.toml file, or by adding a build.rs file (which is a Rust build script) with a cbingen builder. The documentation offers examples of configuration options.
(L2.2) Best practices regarding Rust and security
There are many kinds of insecurity, however, Rust was designed to eliminate one prevalent kind, namely, memory errors. All a programmer has to do to avoid writing memory errors in Rust is not to use any unsafe Rust superpowers. Which means you have to stick to the Rust ownership model:
- Each value in Rust has an owner.
- There can only be one owner at a time.
- When the owner goes out of scope, the value will be dropped.
Rust does not automatically ensure complete security in every aspect, so it is crucial to consider other security aspects, such as keeping dependencies up to date and secure. The cargo audit tool can help with this as it verifies that the libraries used in a Rust project are secure. Specifically, it examines all the project's dependencies and checks them against the RustSec Advisory Database to identify any known security vulnerabilities. Other well-known resources for helping with security are for instance the OWASP Top 10 for web security, and security by design practices.
The rest of this report will focus specifically on avoiding memory errors and their consequences in Rust.
Memory Errors
While it seems straightforward to not write any memory errors in Rust, as all a programmer has to do is not write any unsafe Rust, it is not that straightforward. It is not always possible to avoid unsafe code due to performance requirements, design choices, or the need for low-level control such as Direct Memory Access. When the design requirements cannot be met inside the stringent rules safe Rust imposes, you can use unsafe Rust, which allows the programmer to disregard all safe Rust rules but cannot give any memory safety guarantees.
This report contains the guarantees that unsafe code blocks can provide and some guidelines on the correct use of unsafe Rust. For more in depth or specific guidelines visit the Rustnomicon, the official unsafe Rust documentation.
Guarantees Provided By Unsafe Rust Blocks
Unsafe blocks, as shown below, unlock the use of unsafe Rust.
unsafe {
let val = *ptr;
}
There are five superpowers that unsafe Rust gives a programmer access to:
- Dereference c-style pointers
- Call unsafe functions
- Implement unsafe traits
- Mutate statics
- Access fields of unions
While unsafe blocks grant access to Rust's "unsafe superpowers," they do not disable Rust's safety checks. Code that is not directly using the five unsafe capabilities is still subject to Rust's ownership rules. For instance, the compiler will reject code that creates two mutable references to the same object simultaneously, as this violates the ownership model. If a programmer needs two pointers to the same object, they must use C-style raw pointers and apply the appropriate unsafe superpower when dereferencing them.
unsafe {
let val = 8:
let ref1 = &mut val;
let ref2 = &mut val;
safe_function(ref1, ref2);
}
Guidelines for Memory Safe Unsafe Rust
While the Rustnomicon provides more extensive documentation, here we cover how to avoid the more common causes of memory unsafe unsafe Rust.
Unsafe Standard Library APIs
There are quite a few unsafe functions and traits provided by the standard library. When using any unsafe API, the most important step to avoid undefined behavior is reading the documentation carefully. The standard library documentation provides all prerequisites that the calling code must fulfil to avoid triggering undefined behavior. When a program makes use of an unsafe function always (as recommended by the Rustnomicon) add a comment to the code explaining why the prerequisites are met. This way other collaborators can verify whether the conclusion on whether or not the call was memory safe is correct and when any code is changed it is easy to check whether all prerequisites still hold.
Transmute
Transmute allows you to change the type of a piece of data. The only restriction is that the new type must be the same size as the original. Transmute can cause undefined behavior in many different ways, not least of which are the ramifications of transmuting between two different compound types as the types may have a different internal layout. This problem is exacerbated by the not precisely defined layout of Rust structures.
Be cautious when transmuting to a reference, as failing to explicitly specify the lifetime can result in an unbounded reference. Cui et al. (2024) have shown that combining lifetimes with unsafe code can be risky, so always carefully consider the implications before creating a reference.
The most dangerous of the transmute's capabilities is the ability to change an immutable variable to a mutable reference. However, this should never be attempted because it is undefined behavior. The Rust compiler makes assumptions based on the original guarantee that the reference will never be mutable. Therefore, if you break the immutability contract there is no telling what can go wrong.
Using the Send and Sync Trait
One of the most common causes of memory errors in Rust according to Cui et al. (2024) is the incorrect use of the Send and Sync trait. If performance is not an issue, the safer option is to make use of synchronization primitives.
Optimizations
One common unsafe optimization is turning off bounds checks, however, Popescu at al. (2021) have shown that turning off bounds checks does not always improve performance. This finding is relevant for bounds checks and any optimization that introduces unsafety. Make sure that your optimization has a significant impact before offering up security. This also goes for multithreading as even in Rust it can be a hard problem, especially since race conditions, unlike data races, are not considered unsafe by Rust. This means that there are no handrails provided to avoid race conditions.
Guidelines for Safe Unsafe Rust
It is not enough to ensure that your unsafe Rust code does not exhibit undefined behavior. The unsafe code should be contained, easy to verify, and easy to find should there be undefined behavior. To contain it, it should be separated from the rest of the program in designated unsafe zones. This way, if there is an issue, you immediately know where to look.
Unsafe Zones
Ideally, the unsafe zones you created expose a completely safe API by making sure all possible checks are done inside the unsafe zone so no matter the input into the unsafe API no memory errors can be triggered. If a function can be provided inputs that trigger undefined behavior inside the function and these inputs are impossible to filter out, the function must be marked unsafe. An unsafe function must provide documentation on which prerequisites must hold when called so that no undefined behavior can occur. Every call site of an unsafe function must include an accompanying comment that explains how exactly all the prerequisites are satisfied. This makes it easier for the developer and possible collaborators to verify that the prerequisites still hold, even if there have been program changes.
Any unsafe block, not only those that call unsafe functions should provide such an explanation, even those in the designated unsafe zones.
The Reach of Memory Unsafe Unsafe Rust
While memory errors are made possible in unsafe code, they can be caused by safe code and are often triggered in safe code. For example, doing pointer arithmetic is not one of the unsafe superpowers, so it is possible in safe code. Of course, this pointer cannot be accessed without the help of unsafe code.
In the code below the invalid ptr_b is created by adding the offset 10 to ptr_a. A segmentation fault occurs in unsafe code, where most people would expect it.
{
let ptr_a = ref to ptr;
let ptr_b = ptr_a + 10; // Invalid pointer creation
unsafe {
let val = *ptr_b; // Segfault here
}
}
The code below shows how undefined behavior can be triggered in safe code. If an invalid ptr_b is transformed into a reference in unsafe code, any access of that reference in safe code will result in undefined behavior. This means that your safe code can trigger something like a segmentation fault or even under the right circumstances successfully perform an out-of-bounds read.
{
unsafe{
let ref_b = ptr_b to ref;
}
let val = *ref_b;
}
In conclusion:
- The cause of the undefined behavior a program exhibits, may not be the unsafe code. This is why adding a comment on why your unsafe block is safe is so important. If there is undefined behavior all you then have to do is search for your unsafe code blocks and figure out whether your prerequisites for safety were incomplete or whether they weren't satisfied by your safe code.
- Undefined behavior can still occur in your safe code. This means, for example, that not because sensitive data is only ever handled by safe code this data is incorruptible with a little help from unsafe code.
Cross Language attacks
The previous section highlighted how memory-unsafe code can impact safe Rust code, but this is only the beginning of the problem. Mergendahl et al. (2022) and Papaevripides et al. (2021) have demonstrated that the interaction between unsafe code and safe Rust code can introduce unforeseen vulnerabilities.
This is an example of their newfound attack surface: If a C program, secured with perfect Control Flow Integrity (CFI), interacts with Rust, the program is less safe than if all the code was either written in secured C or Rust. This is because CFI and Rust offer memory safety at different levels. While CFI prevents exploits by allowing memory errors to occur but blocking their use, Rust prevents memory errors from occurring in the first place. Therefore, an attacker can corrupt a code pointer in the C code and pass it to the Rust code. Rust, given its defense model, assumes that all data is uncorrupted, therefore, it will treat the code pointer received from the C program as completely valid.
In a broader sense Mergendahl et al. (2022) and Papaevripides et al. (2021) show that great care must be taken when combining code with different, perhaps disjoint, memory safety guarantees. This is not only a problem in the interaction between C security techniques and safe Rust, but also raises concerns for the interaction between safe and unsafe Rust.
In short, it is vital to make sure that the protections that may already be in place, beyond just memory safety, are compatible with Rust safety model or can be effectively integrated into the Rust code.
[1] Samuel Mergendahl, Nathan Burow, and Hamed Okhravi. Cross-language attacks. In NDSS, 01 2022.
[2] Michalis Papaevripides and Elias Athanasopoulos. 2021. Exploiting Mixed Binaries. ACM Trans. Priv. Secur. 24, 2, Article 7 (May 2021), 29 pages. https://doi.org/10.1145/3418898
(L2.3) Overview of research problems
During this project, we delved into three main subjects to do with using Rust for memory safety instead of C/C++:
- How do we make sure our Rust code is memory-safe?
- How do we integrate Rust into existing projects?
- How do we migrate from memory unsafe languages to Rust?
For each point, we came across one big unanswered question. For our first question, the biggest academic interest is which unsafe code is most used, and how dangerous it is.
For the second question, cross-language attacks come into play (see report L2.2). Rust and C/C++ can interact via foreign function interfaces as seen in the 12 December 2023 workshop. However, the advent of cross-language attacks raises an important question: can Rust and C/C++ be combined without compromising security?
Lastly, with the guarantees that Rust offers, there is great interest in automatically migrating from C(/C++) to idiomatic Rust. However, achieving this is still an unsolved problem.
With the White House’s statement encouraging the adoption of memory-safe languages like Rust, we anticipate a continued rise in academic interest across these domains.
1. Which Unsafe Code Is Most Used, and How Dangerous Is It?
Cui et al.(2024), Astrauskas et al. (2020), and Evans et al. 2020 have analyzed the prevalence of unsafe Rust usage. Evans et al. 2020 found that 29% of crates sourced from crates.io use unsafe Rust code directly. Subsequently, Astrauskas et al. (2020) found that 23.6% of the crates from crates.io, evaluated 18 months later, use unsafe Rust. This trend continues with Cui et al.(2024), who found that by 2024 only 20.8% of crates in crates.io use unsafe Rust.
Astrauskas et al. (2020) not only quantified the use of unsafe Rust but also categorized the most common reasons for its use. The top three, in ascending order, are: the use of mutable static variables, dereferences of raw pointers and finally, calls to unsafe functions.
The natural next step is to determine whether using unsafe Rust leads to memory errors and, if so, which kind. Cui et al.(2024) analyze which unsafe standard library APIs are most often misused in such a way that results in a CVE. The most commonly misused standard library APIs for the evaluated CVEs were, in ascending order, APIs that allow indexing without bounds checks, creating uninitialized values, and bypassing thread safety. Specifically the misuse of the unsafe Send and Sync traits was the most common cause for vulnerabilities. Cui et al.(2024) created a standardized collection of safety requirements that can be used in API documentation for clarity to avoid further misuse of unsafe APIs. These safety requirements state which pre or post-conditions the surrounding code must hold to ensure the call to the unsafe API will not cause undefined behavior.
There is still room for further exploration of which unsafe Rust leads to the most CVEs, outside of unsafe APIs, and how the use of unsafe Rust evolves over time.
[1] Cui, M., Sun, S., Xu, H., & Zhou, Y. (2024). Is unsafe an Achilles’ Heel? A Comprehensive Study of Safety Requirements in Unsafe Rust Programming. Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. https://doi.org/10.1145/3597503.3639136
[2] Vytautas Astrauskas, Christoph Matheja, Federico Poli, Peter Müller, and Alexander J. Summers. 2020. How do programmers use unsafe rust? Proc. ACM Program. Lang. 4, OOPSLA, Article 136 (November 2020), 27 pages. https://doi.org/10.1145/3428204
[3] Evans, A. N., Campbell, B., & Soffa, M. L. (2020). Is rust used safely by software developers? Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, 246–257. https://doi.org/10.1145/3377811.3380413
2. Can Rust and C/C++ Be Combined Without Compromising Security?
With the advent of cross-language attacks (see L2.2) new research has emerged to thwart these threats. Li et al. (2022) present their new static analysis tool that aims to detect potential memory management bugs across FFI boundaries. In their tests, they had a false positive rate, i.e. they detected memory management bugs which weren't there, of about 85%. However, they only generated 222 warnings for 49.5 million lines of code. This new tool could, therefore, be very useful for preventing cross-language attacks.
An alternative approach to dealing with cross-language attacks is not to correct the errors which make cross-language attacks possible but to minimize the impact that such an attack can wreak. Liu et al. (2020), Bang et al. (2023), Kirth et al. (2022), Rivera et al. (2021) and, Almohri et al. (2018) propose designs in line with this strategy. These designs share a common principle: protecting data that is only ever touched by safe Rust code in normal code execution from unsafe code. This is done by withdrawing write permissions from the unsafe code to ensure that the safe subsection of data remains uncorrupted. For this design to be effective, the separation of data that unsafe code can legally access from data it cannot must be correct rather than precise. Over-restricting access may alter the program logic should unsafe code be restricted from data it legitimately requires.
[4] Zhuohua Li, Jincheng Wang, Mingshen Sun, and John C. S. Lui. 2022. Detecting Cross-language Memory Management Issues in Rust. In Computer Security – ESORICS 2022: 27th European Symposium on Research in Computer Security, Copenhagen, Denmark, September 26–30, 2022, Proceedings, Part III. Springer-Verlag, Berlin, Heidelberg, 680–700. https://doi.org/10.1007/978-3-031-17143-7_33
[5] Liu, P., Zhao, G., & Huang, J. (2020). Securing unsafe rust programs with XRust. Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, 234–245. https://doi.org/10.1145/3377811.3380325
[6] Bang, I., Kayondo, M., Moon, H., & Paek, Y. (2023). TRust: A Compilation Framework for In-process Isolation to Protect Safe Rust against Untrusted Code. 32nd USENIX Security Symposium (USENIX Security 23), 6947–6964. https://www.usenix.org/conference/usenixsecurity23/presentation/bang
[7] Kirth, P., Dickerson, M., Crane, S., Larsen, P., Dabrowski, A., Gens, D., Na, Y., Volckaert, S., & Franz, M. (2022). PKRU-safe: automatically locking down the heap between safe and unsafe languages. Proceedings of the Seventeenth European Conference on Computer Systems, 132–148. https://doi.org/10.1145/3492321.3519582
[8] Rivera, E., Mergendahl, S., Shrobe, H., Okhravi, H., & Burow, N. (2021). Keeping Safe Rust Safe with Galeed. Proceedings of the 37th Annual Computer Security Applications Conference, 824–836. https://doi.org/10.1145/3485832.3485903
[9] Almohri, H. M. J., & Evans, D. (2018). Fidelius Charm: Isolating Unsafe Rust Code. Proceedings of the Eighth ACM Conference on Data and Application Security and Privacy, 248–255. https://doi.org/10.1145/3176258.3176330
3. How do we go from C Code to idiomatic Rust?
The workshop of 12 December 2023 provides a workflow for manually translating C to Rust code with the help of the tool C2Rust. C2Rust is, after all, the only production-ready tool for automatic translation from C to Rust. However, this tool only performs a syntactical translation, not a semantic one. For example, C pointers are translated to raw pointers in Rust instead of references. Academic interest has now moved to developing a tool that translates C code into idiomatic Rust code automatically. However, to automatically translate C to idiomatic safe Rust, the developer has to prove that the original C code was memory-safe, which academia has struggled to achieve for decades.
Since 2021 [10] academia has made advances in state-of-the-art approaches that surpass C2Rust's capabilities. The new proposals fall into two categories: those based on static analysis and large language models. Both, however, have their limitations.
Static analysis tools generally handle specific changes, such as translating lock mechanisms from the C API to the Rust API [12] or converting a subset of pointers to references [10] [11] [13]. Erme et al. (2023) even propose facilitating a broader scope of transformations by adding changes to the Rust compiler, enabling it to recognize more code patterns as safe.
In contrast, techniques based on large language models can address a much wider variety of unsafe code but suffer from correctness [14] [15]. For instance, according to Takashima et al. (2024) and Eniser et al. (2024), these translated programs fail approximately 50% of the tests in their test suites. To address this, Takashima et al. (2024) introduced Vert to verify whether programs automatically translated from C to Rust retained their original semantics.
The new Translating All C to Rust (TRACTOR) program from DARPA, which aims to automate the translation from legacy C code to Rust can be expected to accelerate further development in this domain.
[10] Emre, M., Schroeder, R., Dewey, K., & Hardekopf, B. (2021). Translating C to safer Rust. Proc. ACM Program. Lang., 5(OOPSLA). https://doi.org/10.1145/3485498
[11] Emre, M., Boyland, P., Parekh, A., Schroeder, R., Dewey, K., & Hardekopf, B. (2023). Aliasing Limits on Translating C to Safe Rust. Proc. ACM Program. Lang., 7(OOPSLA1). https://doi.org/10.1145/3586046
[12] Hong, J., & Ryu, S. (2023). Concrat: An Automatic C-to-Rust Lock API Translator for Concurrent Programs. Proceedings of the 45th International Conference on Software Engineering, 716–728. https://doi.org/10.1109/ICSE48619.2023.00069
[13] Zhang, H., David, C., Yu, Y., & Wang, M. (2023). Ownership Guided C to Rust Translation. In C. Enea & A. Lal (Eds.), Computer Aided Verification (pp. 459–482). Springer Nature Switzerland.
[14] Takashima, Yoshiki (2024). Testing and Verifying Rust's Next Mile. Carnegie Mellon University. Thesis. https://doi.org/10.1184/R1/25451383.v1
[15] Eniser, H. F., Zhang, H., David, C., Wang, M., Christakis, M., Paulsen, B., Dodds, J., & Kroening, D. (2024). Towards Translating Real-World Code with LLMs: A Study of Translating to Rust. https://arxiv.org/abs/2405.11514
(L3.1) Embedded operating systems and frameworks
The RustIEC team wrote an overview paper: Overview of Embedded Rust Operating Systems and Frameworks. It is published in MDPI's special issue: Architectures, Protocols and Algorithms of Sensor Networks - Second Edition.
The paper is available online at https://www.mdpi.com/1424-8220/24/17/5818 and is designed to be readable by a broad audience.
The paper explores Operating Systems and frameworks implemented using the Rust programming language. We compare four prominent Rust-based solutions: two operating systems (Tock and Hubris) and two frameworks (RTIC and Embassy). We evaluate key features such as task scheduling, memory safety, hardware interaction, and networking capabilities, providing a comparative analysis based on performance metrics like interrupt latency and scheduling behavior on an ARM Cortex-M4 platform. The study highlights Rust's advantages over traditional languages like C, including enhanced memory safety and modern concurrency models.
The performance evaluation of interrupt and scheduling latency reveals that Tock has the highest total latency. This is because Tock interrupts a running task and schedules the Interrupt Service Routine (ISR) rather than directly executing the ISR. Additionally, Tock’s handling of the Memory Protection Unit (MPU) introduces further latency.
In contrast, RTIC and Embassy exhibit lower interrupt and scheduling latency. RTIC achieves the lowest latency by leveraging hardware-accelerated scheduling. Embassy, while slightly slower, incurs additional latency due to the overhead of its asynchronous scheduler.
For memory footprint, Tock consists of two main components: the kernel and the applications. The kernel is relatively large compared to other solutions, as it includes a wide range of features that may not be necessary for all applications. Conversely, RTIC and Embassy have a smaller memory footprint since only the required components are included and compiled. Applications built on Tock have a very small memory footprint as it only contains system calls.
Regarding the feature set, Tock offers a rich array of capabilities, including a network stack, MPU support, and hardware abstraction layers accessible via system calls. RTIC and Embassy, on the other hand, focus on real-time performance and low latency. RTIC provides a minimal task scheduler, while Embassy extends its feature set with a task scheduler, asynchronous I/O, and a network stack. Embassy’s network stack is a wrapper around the smoltcp library.
(L3.2) Connected Embedded Devices
While the ecosystem is mostly external to the Rust project,
many functionalities are already available in the default installation.
By default, Rust provides 3 main libarires: core, alloc and std.
The core library is the minimal set of functionality that is available to all Rust programs.
The alloc library provides functionality for allocating memory on the heap,
and thus requires an allocator to be present.
The std library is the standard library that provides the full functionality of Rust,
which often requires a full-fledged operating system to be present.
Bootstrapping a bare-metal program
Altough you can use Rust to write bare-metal programs,
the std library is not available in this context.
Bootstrapping a bare-metal program also requires a custom runtime,
which is platform specific.
For example, the cortex-m-rt crate provides a runtime for ARM Cortex-M microcontrollers.
It takes care of initializing static memory, vector tables and the stack pointer.
You ecosystem also contains runtimes for platforms based on MIPS, RISC-V, or ESP-C architectures,
being mips-rt, riscv-rt
and esp32c-rt respectively.
Note that for the ESP32 series, a fork of the Rust compiler is also provided by Espressif Systems.
This fork provides std support for the ESP32 series.
Peripheral Access Crates (PACs)
Microcontroller peripherals are accessed through registers,
which are memory-mapped to specific addresses.
The description of the registers available on a microcontroller is provided in a Systems View Description (SVD) file.
The svd2rust tool generates Rust code from these files,
providing a safe API to access the peripherals.
These libraries are available as Peripheral Access Crates (PACs).
Here is a list of some of the most popular PACs:
stm32-rsprovides a PAC for all STM32 microcontrollers.nrf-pacsprovides a PAC for common Nordic Semiconductor microcontrollers.esp-pacsprovides a PAC for the ESP32 series.- Other PACs are available for a wide range of microcontrollers.
Hardware Abstraction Layers (HALs)
Using these PACs, Hardware Abstraction Layers (HALs) can be built.
HALs provide a higher-level API to interact with the hardware,
abstracting the low-level details of the microcontroller.
These HALs are usually implementing traits from the embedded-hal libary.
It contains a collection of traits for low-level hardware interfaces,
such as digital I/O, serial communication, and timers.
The advantage of using traits for these interfaces is that it allows for generic programming.
For example, a driver for a specific sensor can be written in a generic way,
so that it can be used with any micrcontroller that implements the embedded-hal traits.
A list of implementations of the embedded-hal traits can be found here.
Note that some operating systems and frameworks also provide their own HALs,
for examples, Embassy provides HALs
that are asynchronous and non-blocking.
Networking and Security
Networking and security are important aspects of embedded systems.
The smoltcp crate provides a TCP/IP stack that is designed for embedded systems.
It is written in pure Rust and is designed to be memory efficient.
For CoAP, the coap-lite crate provides a CoAP implementation in Rust.
The Rust community has also developed a number of security-related crates,
provided by the RustCrypto project.
These crates provide cryptographic algorithms, secure random number generators, and other security-related functionalities.
The rustls crate provides a TLS implementation in Rust,
which is useable in embedded systems.
Another no_std capable TLS implementation is the embedded-tls crate.
A more complete list of the Embedded Rust ecoystem can be found here: Awesome Embedded Rust.
(L4.1) Using Rust in microservices
The broadest category of programs runs in user space. These programs use the standard library of Rust, as opposed to e.g. kernel drivers or embedded systems, like studied in our workshops. Most often, these programs will have external, third-party, dependencies.
In this report, we will look at a possible architecture of a set of microservices, and how Rust can be used to implement them. Our example concerns a chess engine "Crabstick", written in Rust, which is interfacing with Lichess to provide a chess game to users. If you want to try it out, you can challenge Crabstick on Lichess for a live game! Currently, Crabstick will accept standard timed challenges within a specific range of time controls. We suggest you play a 5+3 game.

Writing a chess engine is considered out-of-scope for this project, but we will look at the architecture of Crabstick, and how it can be used as a case study for microservices in Rust.
Lichess exposes game challenges to a bot via a websocket. We decided to capture this event stream via a central "manager" process. The game itself gets assigned to a worker node, which contains the actual engine and logic to make moves. A worker registers itself to the manager through a websocket connection, and the manager will assign games to workers based on their availability.

Manager
The manager consists out of two actors,
which are implemented using the Actix framework.
The first actor is the WorkerSetState, which keeps track of all the workers,
and which games they are playing.
The second actor is a WorkerSocket, which handles the communication to and from a worker.
This actor is started for each worker that connects to the manager.
The manager also concurrently serves an HTTP server to provide a metrics endpoint for Prometheus, and a websocket server for the workers to connect to. The HTTP server is implemented using Actix-web, and is concurrently served on the same thread:
#[actix_web::main] fn main() { // Initialize shared state let worker_set = WorkerSetState::default().start(); // Set up the Lichess listener let mut lichess_api = pin!(handle_lichess_challenges(worker_set.clone()).fuse()); // Expose the HTTP service let mut worker_api = pin!(worker_api(worker_set.clone()).fuse()); // Health check for the worker set. If the WorkerSetState actor crashes, this will stop the program. // It should be possible to asynchronously wait for the WorkerSetState actor to crash, // instead of polling it every 5 seconds, but this should be good enough for now. let mut keep_alive = pin!(async move { while worker_set.connected() { tokio::time::sleep(std::time::Duration::from_secs(5)).await; } Result::<(), _>::Err(anyhow::anyhow!("WorkerSetState actor is not connected")) } .fuse()); futures::select! { res = worker_api => { tracing::warn!("Worker API stopped: {:?}", res); res?; } res = lichess_api => { tracing::warn!("Lichess API stopped: {:?}", res); res?; } res = keep_alive => { res?; } } }
The futures::select! macro is used to concurrently run the HTTP server, the Lichess listener, and the health check,
and ensures that the program wilt halt when any of these tasks fail.
A worker connects via a websocket on the /ws/ HTTP endpoint.
The websocket connection is handed over to a newly started instance of WorkerSocket,
which will handle the communication with the worker.
Actix has all these features built-in, and it is relatively easy to use them.
The manager exposes a /metrics endpoint for Prometheus to scrape.
This is currently manually implemented,
by formatting one large string with metrics.
In practice, it would be cleaner and more future-proof to use a crate like metrics_exporter_prometheus in combination with metrics.

Furthermore,
the manager exposes a /readyz and /livez endpoint for Kubernetes to check the health of the manager.
#![allow(unused)] fn main() { async fn worker_api(worker_set: Addr<WorkerSetState>) -> std::io::Result<()> { HttpServer::new(move || { App::new() .app_data(web::Data::new(worker_set.clone())) .route("/ws/", web::get().to(worker)) .route("/readyz", web::get().to(ready)) .route("/livez", web::get().to(live)) .route("/metrics", web::get().to(metrics)) .route("/shutdown", web::post().to(shutdown)) }) .bind(("0.0.0.0", 8080))? .run() .await } }
The /shutdown endpoint is used to force-stop the worker set, which kills the process.
This endpoint is called by the CI/CD pipeline to force-restart the manager,
to ensure that the manager is always running the latest version of the code.
Lichess only allows one connection per bot, so the manager needs to be briefly shut down to reconnect to Lichess on a new version.
Ongoing games are not canceled,
because the workers are stateful and will continue to play the game until it is finished.
If the worker crashes, the manager will notice this, and forfeit the game.
Workers
The workers are the actual chess engines.
As written above, they connect to the manager over a websocket connection,
and wait until they are assigned a game.
When a game is assigned, the worker will start a new instance of the chess engine,
read the events from a separate websocket connection to Lichess,
and make moves based on the events.
All of this is handled in the async fn play(..) function.
Kubernetes
Finally, the Kubernetes deployment consists out of the manager (with Recreate deployment strategy),
and a fixed number of workers.
The number of workers could, in theory, be automatically upscaled by the manager.
Downscaling is not possible, because the workers are stateful and need to finish their games;
it should be possible to signal to Kubernetes which nodes are idle, and thus preferred for shutdown,
but this is currently unimplemented.
Ideally, the workers would be stateless, such that they can be scaled up and down as needed, without any disconnects.
(L5.1) User space vs kernel space
Writing code in user space and kernel space, whether it be in C or in Rust is very different, mainly because neither the C nor the Rust Standard Library can be used in kernel space. While the Linux kernel provides much requested and used C library functions, the coverage for Rust standard Library functions is far more limited.
In user space, Rust code can make use of the Standard Library and the ecosystem of libraries that build on it. This allows developers to avoid "reinventing the wheel" by using reliable, well-tested libraries. This is particularly advantageous when a project requires unsafe Rust constructs. Many libraries in the Rust ecosystem implement these constructs and expose fully safe APIs, enabling developers to focus on designing their code without worrying about memory safety.
Kernel space is, however, a very different environment. While the goal is also to make sure that developers can use only safe code, achieving this is much harder. In kernel space, only the core Rust library is available and most of the kernel API is still only available in C. The Rust for Linux project aims to create a safe Rust kernel API so driver developers, who are often less experienced or less known to the Linux kernel community, can work entirely in safe Rust. Currently, any developer wanting to create a Rust driver must still contend with unsafe Rust and follow the general good practices for unsafe Rust code development (see report L2.2).
Not only is there far less support to enable writing safe Rust in kernel space, the kernel space API has also been in flux for the last couple of years with many major changes. Currently there is a direct line for upstreaming code from the Rust for Linux Kernel to the mainline Linux kernel, this suggests that while Rust support in the kernel will continue to grow, major design shifts may be behind us for the foreseeable future. The usergroup presentation of june 5th goes over these hardships and changes.
(L5.2) Best practices for reliable drivers
Due to the limited Rust Linux kernel API, any new driver will need to rely heavily on C kernel APIs. General best practices for integrating Rust and C have already been covered in the workshop of 12 December 2023. The course materials can be found here, the slides that introduce the workshop can be found here. The workshop emphasizes that a safe wrapper must encapsulate unsafe code, ensuring that as little unsafe code as possible is present in the core logic. Building on this idea, the Rust for Linux kernel adopts a rule that all foreign function interfaces (FFIs) from C to Rust must be wrapped in a safe Rust wrapper if possible or, if necessary, in an unsafe Rust wrapper. These wrappers must all be added to the Linux core, not the drivers. The goal is, that with time, most interfaces will have a Rust counterpart such that driver developers will no longer need to worry about unsafe code. Therefore, they will not need to worry about memory safety or data races. One-time and unknown contributors are, after all, mostly present in driver code. Driver code is also verified the least, and has the most memory safety issues.
(L5.3) Microbenchmarks for kernel APIs
As presented on june 5th, the Rust for Linux kernel is constantly in flux and even went through a massive overhaul in the last year. The big change, which was necessary for more streamlined upstreaming to the mainline Linux kernel, resulted in even less support for Rust drivers than before. Therefore, any microbenchmarks of the Rust kernel API would be outdated very quickly. Currently the more interesting microbenchmarks are those of Linux drivers written in Rust backed by bigger companies and open source projects.
These companies and open-source projects that are working on Rust drivers, usually do so in their own branch of the Linux kernel. The more stable of these larger projects provide performance benchmarks compared to the old C implementation. There are microbenchmarks available of four different Rust drivers. These benchmarks show that on average the Rust drivers are slightly less performant than the original C drivers.
Microbenchmarks NMVe Driver
These are the latest official results for the NVMe driver. The evolution of results since January 2023 can be found on the Rust for Linux website. While the performance is very similar, the C driver slightly outperforms the Rust driver in most microbenchmarks.
Setup
AMD Ryzen 5 7600
32 GB 4800 MT/s DDR5 on one channel
1x Samsung 990 Pro 1TB (PCIe 4.0 x4 16 GT/S)
NixOS 24.05
Results
40 samples
Difference of means modeled with t-distribution
P95 confidence intervals
 https://rust-for-linux.com/nvme-driver
https://rust-for-linux.com/nvme-driver
 https://rust-for-linux.com/nvme-driver
https://rust-for-linux.com/nvme-driver
Microbenchmarks Null Block Driver
The null block driver has made it into the mainline Linux kernel and, as can be seen below, has comparative but slightly worse performance overall compared to the C driver. These mcirobenchmarks are sourced from the Rust for Linux website.
Setup
AMD Ryzen 5 7600
32 GB 4800 MT/s DDR5 on one channel
1x Samsung 990 Pro 1TB (PCIe 4.0 x4 16 GT/S)
NixOS 24.05
Results
Plot shows (mean_iops_r - mean_iops_c) / mean_iops_c
40 samples for each configuration
Difference of means modeled with t-distribution
P95 confidence intervals
 https://rust-for-linux.com/null-block-driver
https://rust-for-linux.com/null-block-driver
Microbenchmarks Binder and e1000
The latency microbenchmarks that are provided by Hongyu Li et al. (2024) for e1000 and binder show that the Rust version in both cases has a higher latency. The Rust e1000 driver latency is 11 times higher than the C driver, however, this is deemed to be due a lack of features available in the Rust version that are not present in the C driver. Therefor, this is not an indication that the Rust driver is inherently slower due to the difference in language.
The binder drivers have a more comparable latency, with Rust having a 10% higher latency.
 https://www.usenix.org/conference/atc24/presentation/li-hongyu
https://www.usenix.org/conference/atc24/presentation/li-hongyu
(L6.1) Embedded Pong: Async Rust on nRF52840-DK
This project demonstrates an embedded Pong game implementation on the nRF52840 Development Kit using Rust's async programming capabilities. The implementation leverages the Embassy framework, Rust's type system, and modern embedded libraries to create a functional game on a microcontroller, showcasing the potential of async Rust in embedded systems development.
System Architecture
The system is built around several key technological components. At its core is the Embassy framework, which provides an async runtime specifically designed for embedded systems. This allows for more efficient and readable concurrent programming compared to traditional bare-metal approaches. The primary hardware components include a ST7735S 1.77" SPI display for rendering game graphics and the nRF52840's integrated buttons for user input.
Rust's type system plays a crucial role in the implementation, providing compile-time guarantees of memory safety and preventing common embedded programming pitfalls. Unlike traditional C-based embedded development, Rust ensures memory safety without runtime overhead, making it particularly attractive for resource-constrained environments.
Execution Model
One of the most sophisticated aspects of the implementation is its multi-priority executor design. The system utilizes two distinct executors:
- High-Priority Executor: Dedicated to time-critical tasks such as input handling and interrupt management.
- Low-Priority Executor: Manages background operations and less time-sensitive tasks.
This hierarchical approach allows for fine-grained control over task scheduling.
The SWI0_EGU0 interrupt is configured to enable the executor to wake from sleep states,
striking a balance between system responsiveness and power efficiency.
Input Handling
Input management demonstrates the power of Embassy's async primitives.
The input handler uses the select4 method to concurrently monitor four buttons on the nRF52840-DK.
This approach provides non-blocking input detection, crucial for responsive game interactions.
#![allow(unused)] fn main() { #[embassy_executor::task] async fn input_handler(btns: (AnyPin, AnyPin, AnyPin, AnyPin)) { let mut btn1 = Input::new(btns.0, Pull::Up); let mut btn2 = Input::new(btns.1, Pull::Up); let mut btn3 = Input::new(btns.2, Pull::Up); let mut btn4 = Input::new(btns.3, Pull::Up); loop { select4( btn1.wait_for_any_edge(), btn2.wait_for_any_edge(), btn3.wait_for_any_edge(), btn4.wait_for_any_edge(), ) .await; // Input processing logic info!( "Detected input change 1: {}, 2: {}, 3: {}, 4: {}", btn1.is_low(), btn2.is_low(), btn3.is_low(), btn4.is_low() ); } } }
Display Rendering
Graphics rendering leverages the embedded-graphics library, providing a high-level abstraction for pixel manipulation. The implementation uses a frame buffer approach, allowing for efficient graphics preparation before transferring data to the ST7735S display via asynchronous SPI communication.
The display task demonstrates several advanced Rust embedded programming techniques:
- The display task demonstrates several advanced Rust embedded programming techniques:
Mutexfor thread-safe shared state- Asynchronous SPI communication
- Efficient memory management
#![allow(unused)] fn main() { #[embassy_executor::task] async fn async_driver(back_buffer: FrameBufferRef, static_driver: DisplayRef, signal: SignalRef) { loop { if !signal.signaled() { signal.wait().await; } { let fb = back_buffer.lock().await; let drawable_area = fb.size(); unwrap!( static_driver .set_pixels_buffered( 0, 0, drawable_area.width as u16 - 1, drawable_area.height as u16 - 1, fb.as_ref().iter().map(|&c| RawU16::from(c).into_inner()), ) .await ); } signal.reset(); yield_now().await; } } }
Technical Challenges and Solutions
Several technical challenges were addressed during the implementation:
- Concurrency Management: Embassy's async runtime allows for efficient task switching without traditional threading overhead
- Memory Safety: Rust's ownership model and borrowing rules prevent common memory-related bugs.
- Low-Level Hardware Interaction: Trait-based abstractions in Embassy and embedded-hal provide clean interfaces for hardware communication.
Performance Considerations
The implementation prioritizes both performance and power efficiency. The use of async tasks allows for:
- Minimal context switching overhead
- Efficient use of microcontroller resources
- Responsive input handling
- Low-power operation through intelligent task scheduling
Conclusion
This project demonstrates the viability of async Rust in embedded game development. By combining the Embassy framework with Rust's type system and zero-cost abstractions, we created a robust, efficient, and readable embedded application. The implementation serves as a practical example of how modern programming techniques can be applied to resource-constrained systems.