(L4.1) Using Rust in microservices
The broadest category of programs runs in user space. These programs use the standard library of Rust, as opposed to e.g. kernel drivers or embedded systems, like studied in our workshops. Most often, these programs will have external, third-party, dependencies.
In this report, we will look at a possible architecture of a set of microservices, and how Rust can be used to implement them. Our example concerns a chess engine "Crabstick", written in Rust, which is interfacing with Lichess to provide a chess game to users. If you want to try it out, you can challenge Crabstick on Lichess for a live game! Currently, Crabstick will accept standard timed challenges within a specific range of time controls. We suggest you play a 5+3 game.
Writing a chess engine is considered out-of-scope for this project, but we will look at the architecture of Crabstick, and how it can be used as a case study for microservices in Rust.
Lichess exposes game challenges to a bot via a websocket. We decided to capture this event stream via a central "manager" process. The game itself gets assigned to a worker node, which contains the actual engine and logic to make moves. A worker registers itself to the manager through a websocket connection, and the manager will assign games to workers based on their availability.

Manager
The manager consists out of two actors,
which are implemented using the Actix framework.
The first actor is the WorkerSetState, which keeps track of all the workers,
and which games they are playing.
The second actor is a WorkerSocket, which handles the communication to and from a worker.
This actor is started for each worker that connects to the manager.
The manager also concurrently serves an HTTP server to provide a metrics endpoint for Prometheus, and a websocket server for the workers to connect to. The HTTP server is implemented using Actix-web, and is concurrently served on the same thread:
#[actix_web::main] fn main() { // Initialize shared state let worker_set = WorkerSetState::default().start(); // Set up the Lichess listener let mut lichess_api = pin!(handle_lichess_challenges(worker_set.clone()).fuse()); // Expose the HTTP service let mut worker_api = pin!(worker_api(worker_set.clone()).fuse()); // Health check for the worker set. If the WorkerSetState actor crashes, this will stop the program. // It should be possible to asynchronously wait for the WorkerSetState actor to crash, // instead of polling it every 5 seconds, but this should be good enough for now. let mut keep_alive = pin!(async move { while worker_set.connected() { tokio::time::sleep(std::time::Duration::from_secs(5)).await; } Result::<(), _>::Err(anyhow::anyhow!("WorkerSetState actor is not connected")) } .fuse()); futures::select! { res = worker_api => { tracing::warn!("Worker API stopped: {:?}", res); res?; } res = lichess_api => { tracing::warn!("Lichess API stopped: {:?}", res); res?; } res = keep_alive => { res?; } } }
The futures::select! macro is used to concurrently run the HTTP server, the Lichess listener, and the health check,
and ensures that the program wilt halt when any of these tasks fail.
A worker connects via a websocket on the /ws/ HTTP endpoint.
The websocket connection is handed over to a newly started instance of WorkerSocket,
which will handle the communication with the worker.
Actix has all these features built-in, and it is relatively easy to use them.
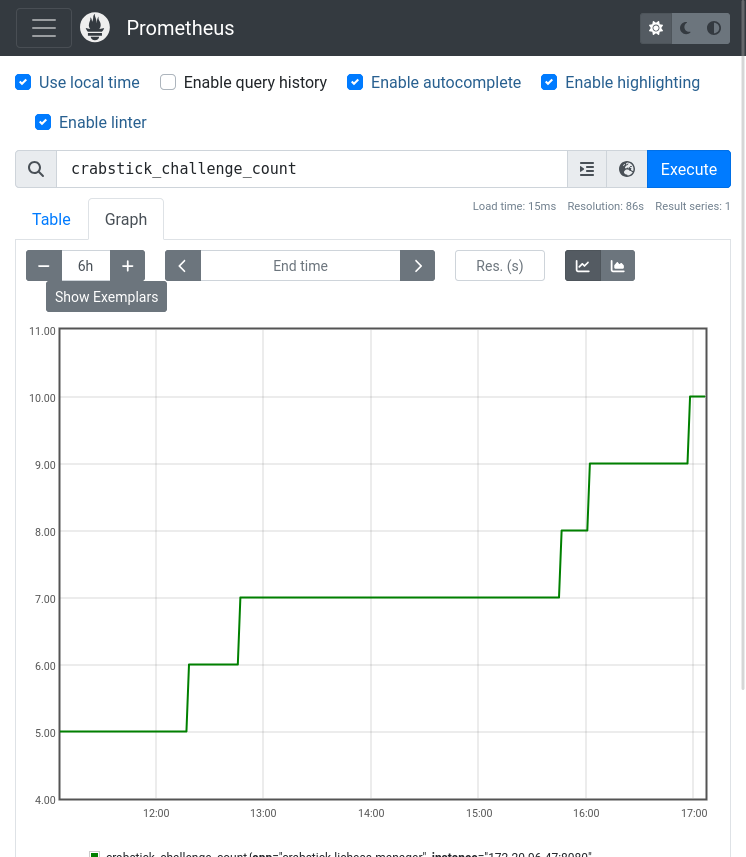
The manager exposes a /metrics endpoint for Prometheus to scrape.
This is currently manually implemented,
by formatting one large string with metrics.
In practice, it would be cleaner and more future-proof to use a crate like metrics_exporter_prometheus in combination with metrics.
Furthermore,
the manager exposes a /readyz and /livez endpoint for Kubernetes to check the health of the manager.
#![allow(unused)] fn main() { async fn worker_api(worker_set: Addr<WorkerSetState>) -> std::io::Result<()> { HttpServer::new(move || { App::new() .app_data(web::Data::new(worker_set.clone())) .route("/ws/", web::get().to(worker)) .route("/readyz", web::get().to(ready)) .route("/livez", web::get().to(live)) .route("/metrics", web::get().to(metrics)) .route("/shutdown", web::post().to(shutdown)) }) .bind(("0.0.0.0", 8080))? .run() .await } }
The /shutdown endpoint is used to force-stop the worker set, which kills the process.
This endpoint is called by the CI/CD pipeline to force-restart the manager,
to ensure that the manager is always running the latest version of the code.
Lichess only allows one connection per bot, so the manager needs to be briefly shut down to reconnect to Lichess on a new version.
Ongoing games are not canceled,
because the workers are stateful and will continue to play the game until it is finished.
If the worker crashes, the manager will notice this, and forfeit the game.
Workers
The workers are the actual chess engines.
As written above, they connect to the manager over a websocket connection,
and wait until they are assigned a game.
When a game is assigned, the worker will start a new instance of the chess engine,
read the events from a separate websocket connection to Lichess,
and make moves based on the events.
All of this is handled in the async fn play(..) function.
Kubernetes
Finally, the Kubernetes deployment consists out of the manager (with Recreate deployment strategy),
and a fixed number of workers.
The number of workers could, in theory, be automatically upscaled by the manager.
Downscaling is not possible, because the workers are stateful and need to finish their games;
it should be possible to signal to Kubernetes which nodes are idle, and thus preferred for shutdown,
but this is currently unimplemented.
Ideally, the workers would be stateless, such that they can be scaled up and down as needed, without any disconnects.